Building an LLM-powered user review summarization app

Summarizing large amounts of qualitative user feedback is one of the common use cases for LLMs that are currently being explored among user researchers (the empirical data supporting this claim being my LinkedIn feed). In a 3-day project at Data Science Retreat Berlin, I dived a bit deeper into this topic and built a web app that generates summaries of user feedback and product recommendations. This post is about some of the learnings I had developing this app.
App demo
Before diving in, here is a quick demo of the app for context. Try it yourself here.
Lessons learned
1. Streamlit is self-explanatory until it isn’t
Streamlit makes building powerful (and pretty) data science apps incredibly simple. Initially it felt like building an app with something like markdown. However, things got a little confusing once slightly more advanced functionality was needed, such as more user interactions that depend on each other.
Understanding session state was crucial, as well as keeping in mind that Streamlit re-runs the entire app script after every user interaction. At the beginning, buttons worked in unexpected ways when creating them directly in the context of an if-clause (if st.button) and sections of the app suddenly disappeared. Fortunately, this seems to be such a common pitfall that the Streamlit team wrote an extensive explanation about the topic.
For a multi-step process like in this app, the most useful solution was a session state value representing the current stage of the process (st.session_state.stage). The different parts of the app can then be shown conditional on this stage value, and any button can change the stage using a callback function (on_click=set_stage()). Like that it was easy to coordinate the multiple steps of loading reviews, estimating API cost, and generating summaries.
2. LLMs are confident even with insufficient data
Probably it’s because I didn’t use very sophisticated prompts, but it turned out that the LLMs often generalized the provided user feedback and made it sound like all issues affect all users. Quantifiers such as “one/some/most/all user(s)” were rarely used. It felt like the LLMs “assumed” that the provided reviews are an exhaustive representation of all users’ opinions and perceptions. This reminded me of the WYSIATI bias that’s very much present in humans as well (“what you see is all there is”).
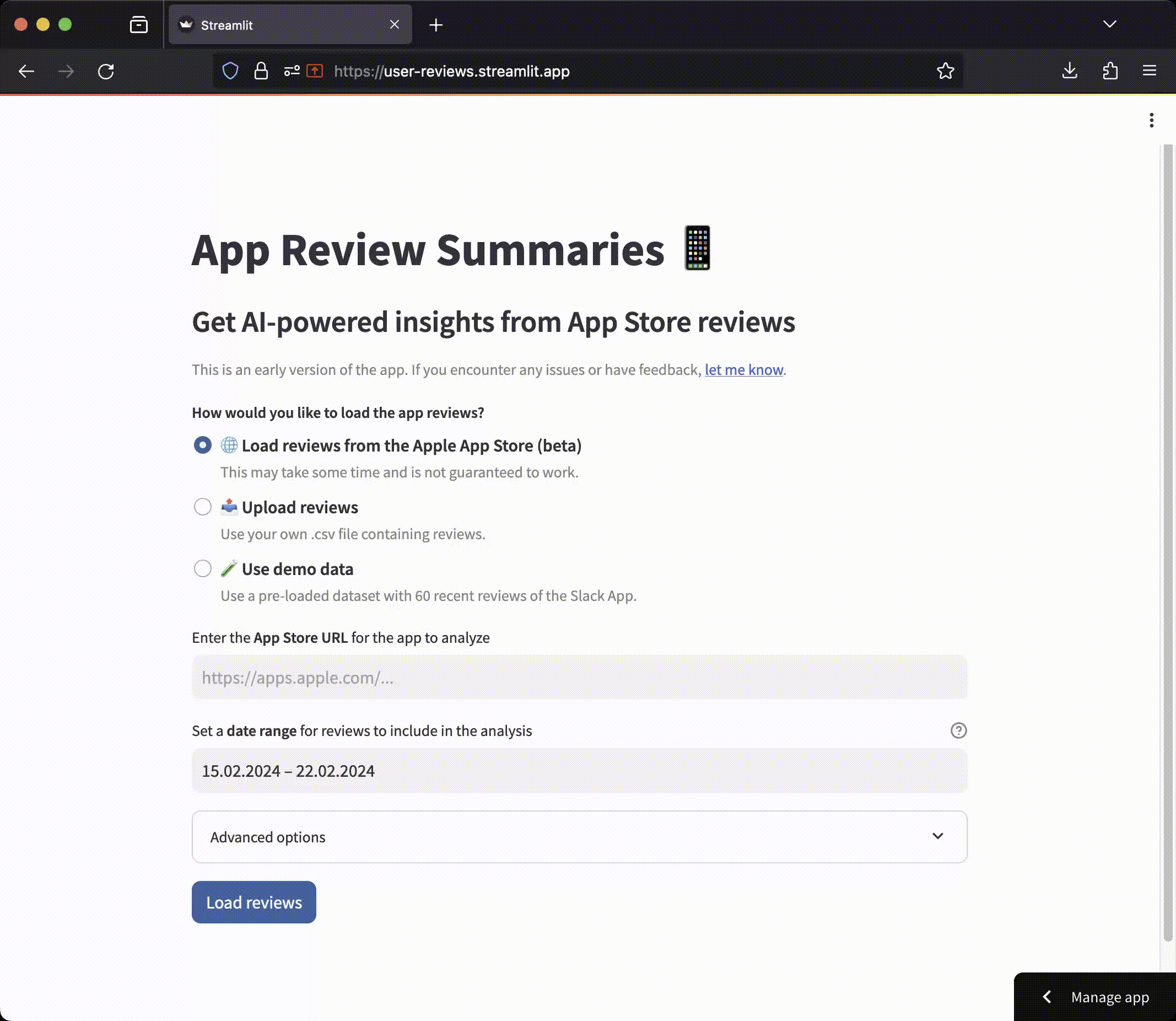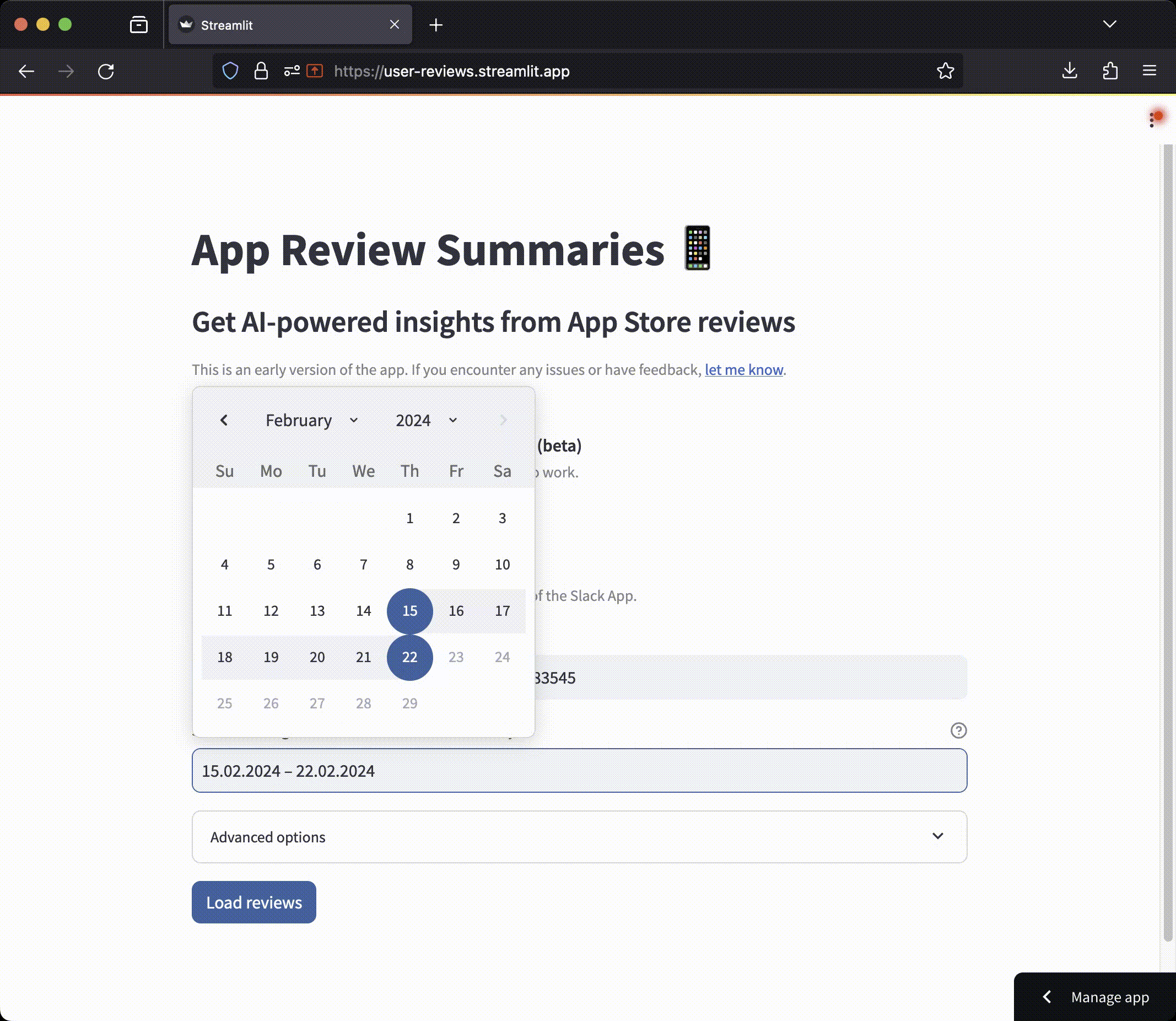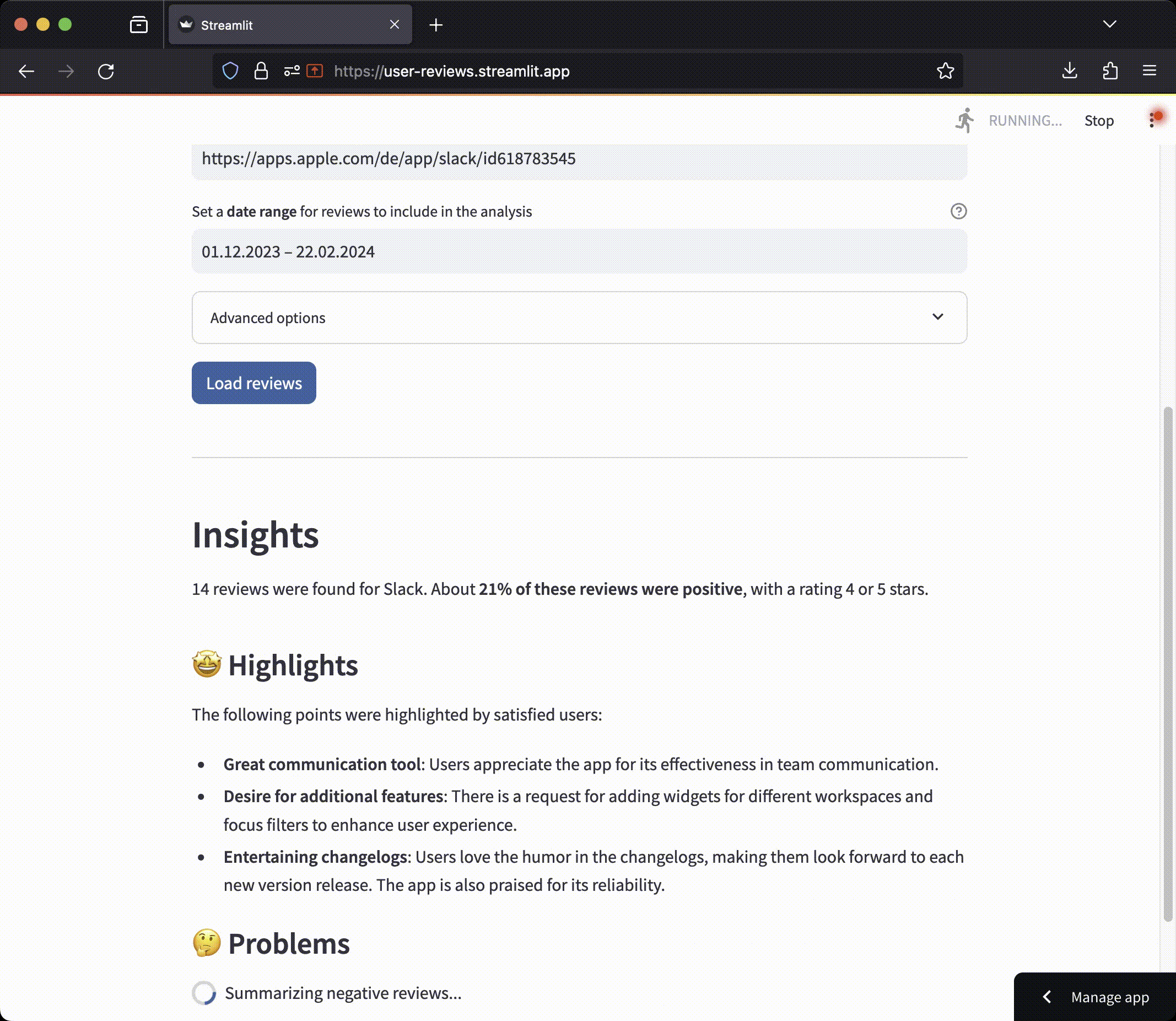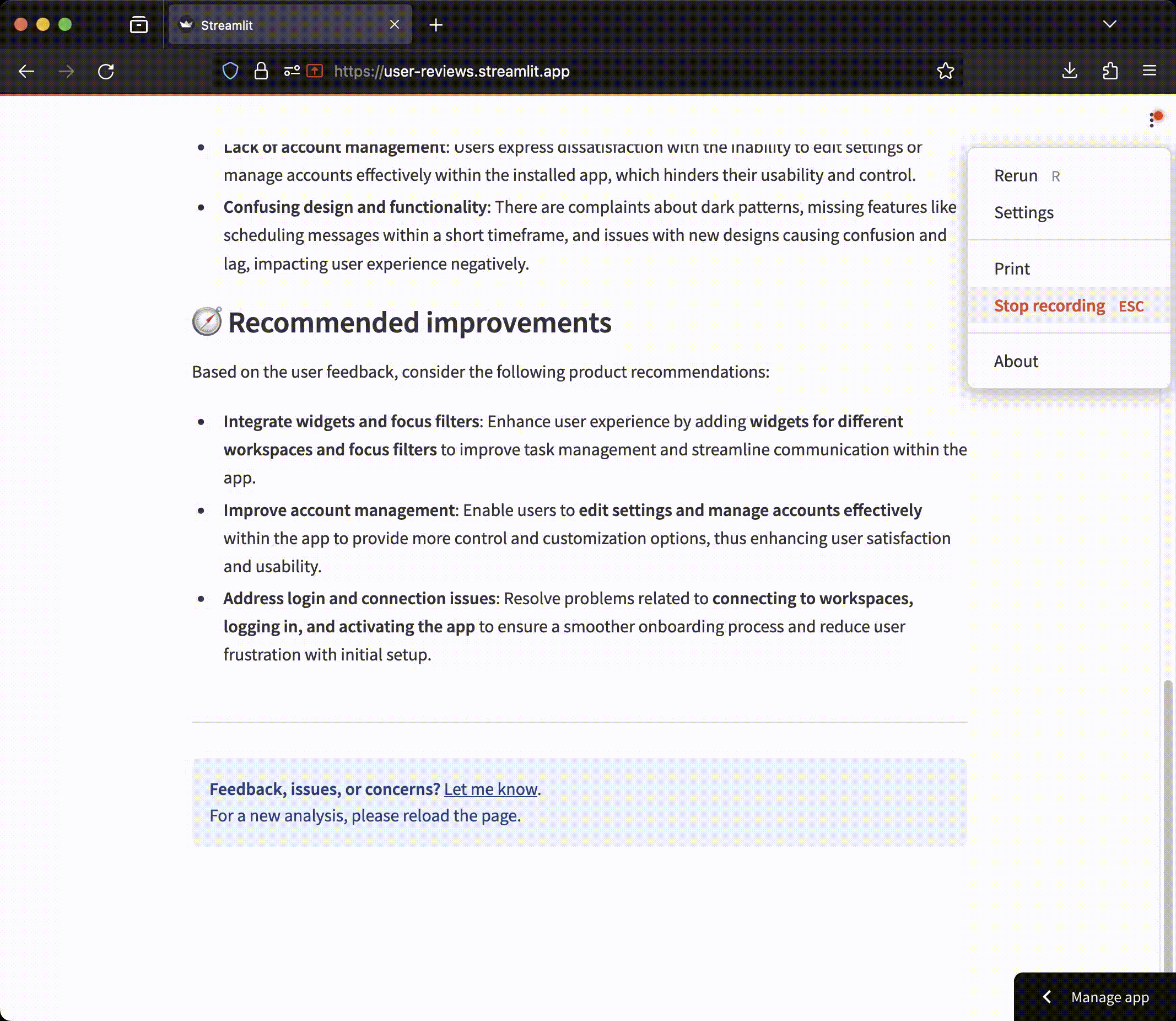
The LLMs also often created quite generic summaries and recommendations at a level of abstraction that’s not actionable for decision-making. For example, a recommendation called “improve usability”.
In general, these issues were less problematic with GPT-4 compared to GPT-3.5, but you definitely can’t rely on getting consistently useful results with any model—at least not without significantly refining the prompts. It might help to explicitly inform the model about the limitations of the data, instruct it to use quantifiers, and implement additional guardrails to make the output more reliable.
 An example of generic and non-actionable recommendations generated by GPT-3.5. Note that most bullet points are rather unspecific and mix topics that are unrelated. The third bullet point illustrates this especially well.
An example of generic and non-actionable recommendations generated by GPT-3.5. Note that most bullet points are rather unspecific and mix topics that are unrelated. The third bullet point illustrates this especially well.
3. Dependencies are a headache
Once the app was running locally in the intended way, I naively expected that it would run just as fine when deployed on Streamlit. However, this is when a few issues with dependencies came up. The main problem was that the user reviews are loaded with an older package that was archived in 2021. This package in turn relied on a pretty old version of the requests package, while Streamlit itself expected a newer version of this package.
My first attempt at fixing this was downgrading my Streamlit version, but this caused other parts of the code to break because they required newer Streamlit functionality. In the end I forked the user review loader package and tried loosening its requirements. This was easier than expected. I changed the requirements.txt file to remove the version specification for the requests package. Luckily for me, the review loader kept working as before.
A small issue remained where the review loader sometimes kept running forever without any progress. As a fix, I wrapped it into a function with a timeout option. In the current version of the app, the review loader runs in a separate thread that is abandoned if it doesn’t finish after a certain time. That doesn’t seem like the most elegant solution, but at least the app now generates an error instead of silently stopping to work.
4. Working with API keys
I wanted to create an app that anyone can use right away without technical knowledge. However, using OpenAI’s models requires an API key, which many users may not want to create. When I noticed that creating the summaries usually cost close to nothing with GPT-3.5, I created a dedicated API key for this app and added some credits. This key is now stored in the Streamlit app’s secrets, and users can run limited analyses with GPT-3.5.
I definitely wanted to include a GPT-4 option as well, especially after noticing the analytical limitations with GPT-3.5 that I mentioned above. Users who prefer a higher-quality analysis can therefore enter their own API key and use GPT-4 for this app. I would be hesitant to enter my API key in a random web app, so I added a rough cost prediction for increased trust and credibility.
Limitations and areas for improvement
Overall, the app is still quite simple and naive. Loading the app reviews from the App Store does not always work reliably given the dependency on the outdated package. Even with GPT-4, you sometimes get non-actionable and generic results. And most importantly, there seems to be little prioritization in the reported feedback. Sometimes, the most random topics are mentioned at the top of the list (e.g., “Users appreciate Slack’s funny release notes”).
Some of these limitations can probably be addressed by improving the prompts and including additional guardrails (e.g., disclaimers in the case of insufficient data). A bigger improvement might come from using new analytical approaches—for example, clustering the reviews and letting the LLM tackle the most frequently mentioned topics first. It could also be interesting to pick up this project again at some point when open-weight models have significantly improved, so that users need to worry even less about the whole API key topic.
Special thanks to Steven with whom I developed the initial concept for this app.